
Что такое атаки переполнения буфера и как они предотвращаются?
Моррис червяк 1988 был один из тех отраслевых встряхивая опыт , который показал , как быстро червь может распространяться с использованием уязвимости, известной как переполнение буфера или буфера перерасход. Около 6000 из 60 000 компьютеров, подключенных к ARPANET, предшественнику Интернета, были заражены червем Морриса. Хотя эта атака принесла несколько положительных результатов, особенно в том, что она подтолкнула производителей программного обеспечения серьезно относиться к уязвимостям, и в создании первой группы реагирования на компьютерные чрезвычайные ситуации (CERT), эта атака была далеко не последней, в которой использовалось переполнение буфера.
В 2001 году червь Code Red заразил более 359 000 компьютеров, на которых запущено программное обеспечение Microsoft IIS. Code Red искажал веб-страницы и пытался запустить атаки типа «отказ в обслуживании», в том числе на веб-сервере Белого дома.
Затем, в 2003 году, червь SQL Slammer атаковал более 250 000 систем, на которых работало программное обеспечение Microsoft SQL Server. SQL Slammer вызывал сбой маршрутизаторов, значительно замедляя или даже останавливая сетевой трафик в Интернете. Черви Code Red и SQL Slammer распространяются через уязвимости переполнения буфера.
Спустя более тридцати лет после червя Морриса мы все еще страдаем от уязвимостей переполнения буфера со всеми их негативными последствиями. Хотя некоторые винят различные языки программирования или их особенности в небезопасном дизайне, виной всему, скорее, ошибочное использование этих языков. Чтобы понять, как происходит переполнение буфера, нам нужно немного знать о памяти, особенно о стеке, и о том, как разработчикам программного обеспечения необходимо тщательно управлять памятью при написании кода.
Что такое буфер и как происходит его переполнение?
Буфер — это блок памяти, назначенный программной программе операционной системой. Программа обязана запросить у операционной системы объем памяти, необходимый для правильной работы. В некоторых языках программирования, таких как Java, C #, Python, Go и Rust, управление памятью выполняется автоматически. В других языках, таких как C и C ++, программисты должны вручную управлять выделением и освобождением памяти и следить за тем, чтобы границы памяти не пересекались, проверяя длину буфера.
Однако ошибки могут быть сделаны программистами, которые неправильно используют библиотеки кода, или теми, кто их пишет. Это причина многих уязвимостей программного обеспечения, готовых к обнаружению и использованию. Правильно разработанная программа должна указывать максимальный размер памяти для хранения данных и гарантировать, что этот размер не будет превышен. Переполнение буфера происходит, когда программа записывает данные за пределами назначенной ей памяти в смежный блок памяти, предназначенный для другого использования или принадлежащий другому процессу.
Поскольку существует два основных типа переполнения буфера — на основе кучи и на основе стека, следует указать предварительное слово, касающееся разницы между кучей и стеком.
Стек против кучи
Перед выполнением программы загрузчик назначает ей виртуальное адресное пространство, которое включает адреса как кучи, так и стека. Куча — это блок памяти, который используется для глобальных переменных и переменных, которым назначается память во время выполнения (выделяется динамически).
Подобно стопке тарелок в буфете, программный стек состоит из фреймов, содержащих локальные переменные вызываемой функции. Фреймы помещаются в стек при вызове функций и выгружаются (удаляются из) при возврате. Если есть несколько потоков, значит, есть несколько стеков.
Стек работает очень быстро по сравнению с кучей, но у его использования есть два недостатка. Во-первых, память стека ограничена, что означает, что размещение больших структур данных в стеке быстрее исчерпывает доступные адреса. Во-вторых, у каждого кадра есть время жизни, ограниченное его существованием в стеке, что означает, что доступ к данным из кадра, который был извлечен из стека, недопустим. Если нескольким функциям требуется доступ к одним и тем же данным, лучше поместить данные в кучу и передать указатель на эти данные (их адрес) этим функциям.
Переполнение буфера может происходить как в куче, так и в стеке, но здесь мы сосредоточимся на более распространенной разновидности: переполнение буфера на основе стека.
Переполнение стека буфера: перезапись адреса возврата
Поскольку фреймы накладываются друг на друга при каждом вызове функции, адреса возврата также помещаются в стек, сообщая программе, где продолжить выполнение после завершения вызываемой функции:
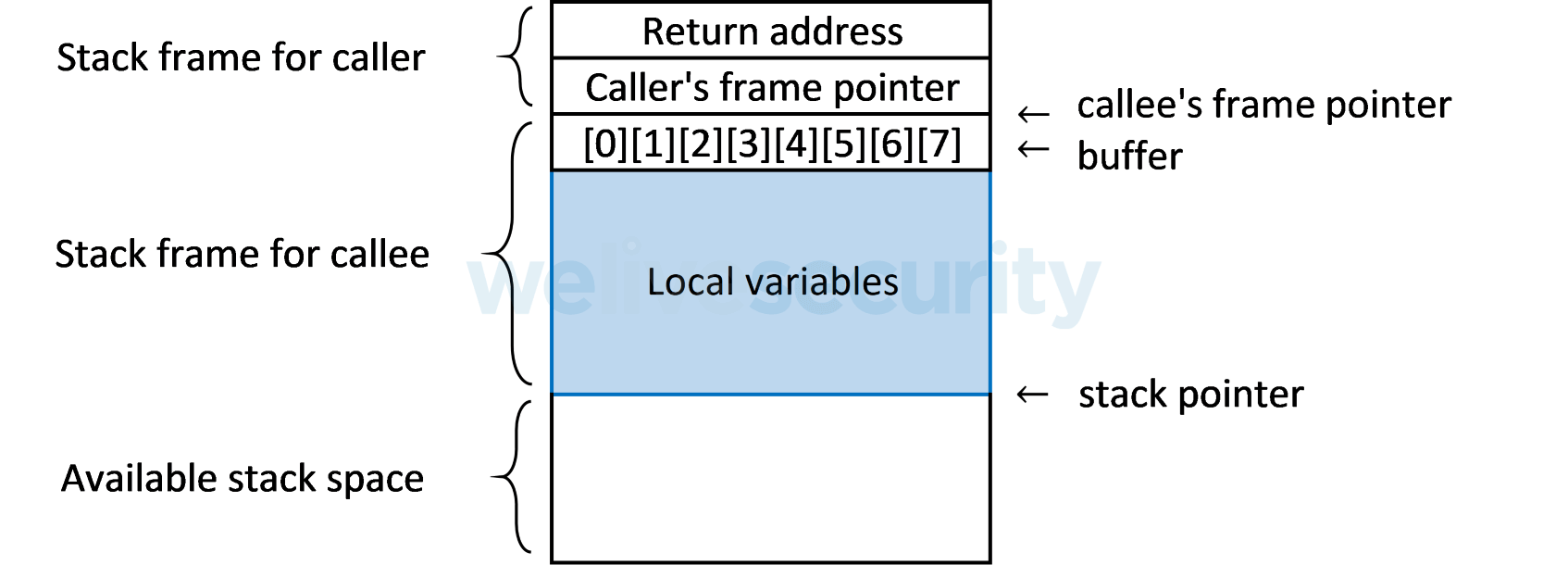
Адрес возврата расположен рядом с буферами, в которых хранятся локальные переменные. Следовательно, если вредоносной программе удается записать в буфер больше данных, чем она может вместить, происходит переполнение буфера. Данные, которые не помещаются в предназначенный буфер, могут вылиться в адрес возврата и перезаписать его.
Если при типичном использовании уязвимой программы происходит переполнение буфера, чаще всего новое значение перезаписанного адреса возврата не является допустимым местом в памяти, а это означает, что программа генерирует ошибку сегментации памяти и потребует исправления ошибки — если это так. невозможно, программа может стать нестабильной или даже аварийной, когда она попытается вернуться из функции, чей кадр стека был изменен переполнением. Однако киберпреступники могут воспользоваться преимуществами переполнения буфера, чтобы перезаписать адрес возврата действительным участком памяти, который указывает непосредственно на их вредоносный код, что позволяет им во многих случаях запускать оболочки и получать полный контроль над компьютерами-жертвами. Червь Stuxnet , например, использовал уязвимость переполнения буфера для запуска корневой оболочки.
Некоторые коды эксплойтов даже используют умный подход к восстановлению повреждений стека после выполнения злонамеренного действия, чтобы восстановить исходный адрес возврата. Таким образом злоумышленники пытаются скрыть захват инструкции возврата, позволяя программе работать должным образом после этого.
Пример — кодирование шестнадцатеричных символов как байтовых значений
Для разработчиков программного обеспечения, заинтересованных в недавнем переполнении буфера, обнаруженном в 2021 году, мы предлагаем следующий код на языке C, который представляет собой упрощенную и переписанную версию уязвимости в маршрутизаторе ZTE MF971R LTE, отслеживаемую как CVE ‑ 2021‑21748 :
Приведенная выше программа демонстрирует функцию, которая кодирует строку, состоящую из шестнадцатеричных совместимых символов, в форму с половиной потребности в памяти. Два символа могут стоять как фактические байтовые значения (в шестнадцатеричном формате), так что символы « 0 » и « 1 », представленные значениями байтов 30 и 31 соответственно, могут быть представлены буквально как значение байта 01 . Эта функция использовалась как часть обработки паролей маршрутизатором ZTE.
Как отмечено в комментариях к коду, hexString , имеющий размер 21 символа, слишком велик для буфера byteValues , который имеет размер только 4 символа (хотя он может принимать до 8 символов в закодированной форме), и нет проверки, гарантирующей, что функция encodeHexAsByteValues не приведет к переполнению буфера.
Защита от атак переполнения буфера
Помимо тщательного программирования и тестирования со стороны разработчиков программного обеспечения, современные компиляторы и операционные системы реализовали несколько механизмов, затрудняющих выполнение атак переполнения буфера. Взяв в качестве примера драйвер компилятора GCC для Linux, мы кратко упомянем два механизма, которые он использует для предотвращения эксплуатации переполнения буфера: рандомизация стека и обнаружение повреждения стека.
Рандомизация стека
Отчасти успех атак на переполнение буфера зависит от знания действительного места в памяти, которое указывает на код эксплойта. В прошлом расположение стека было довольно однородным, поскольку одни и те же комбинации программ и версий операционной системы имели одинаковые адреса стека. Это означало, что злоумышленники могли организовать одну атаку — как один штамм биологического вируса — для атаки на одну и ту же комбинацию программы и операционной системы.
Рандомизация стека выделяет случайное количество места в стеке в начале выполнения программы. Это пространство не предназначено для использования программой, но позволяет программе иметь разные адреса стека при каждом выполнении.
Однако настойчивый злоумышленник может преодолеть рандомизацию стека, неоднократно пытаясь использовать разные адреса. Один из способов — использовать длинную последовательность инструкций NOP (без операции), которые просто увеличивают счетчик программы, в начале кода эксплойта. Тогда злоумышленнику нужно только угадать адрес любой из множества инструкций NOP , вместо того, чтобы угадывать точный адрес начала кода эксплойта. Это называется « салазками NOP », потому что как только программа переходит к одной из этих инструкций NOP , она проходит через остальные NOP до фактического запуска кода эксплойта. Например, червь Морриса запускался с 400 инструкций NOP .
Существует целый класс методов, называемых рандомизацией разметки адресного пространства, чтобы гарантировать, что другие части программы, такие как программный код, код библиотеки, глобальные переменные и данные кучи, будут иметь разные адреса памяти при каждом запуске программы.
Обнаружение повреждения стека
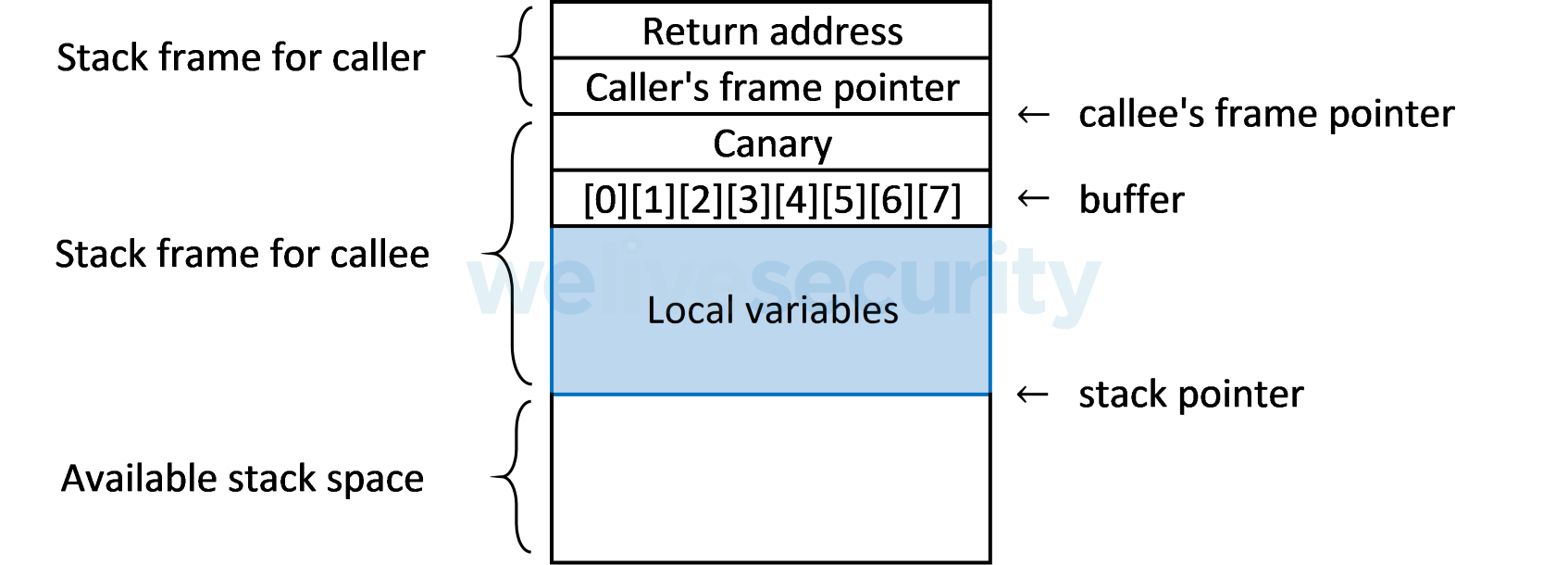
Другой метод предотвращения атаки переполнения буфера — это обнаружение повреждения стека. Обычный механизм известен как средство защиты стека, который вставляет случайное канареечное значение, также называемое защитным значением, между локальными буферами кадра стека и остальной частью стека. Перед возвратом из функции программа может затем проверить состояние канареечного значения и вызвать процедуру обработки ошибок, если переполнение буфера изменило канареечное значение.
Заключительный совет
Поскольку уязвимости переполнения буфера продолжают обнаруживаться и исправляться, лучший совет — иметь надежную политику для исправления всех приложений и библиотек кода с наивысшим приоритетом. Сочетание вашей политики обновления с развертыванием решений безопасности, которые могут обнаруживать код эксплойтов, может значительно повысить ставки против злоумышленников, пытающихся использовать переполнение буфера.









Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.